
Das Tutorial beschreibt wie man eine CSV Datei in MS SQL Server importieren kann, so dass die CSV Datei als Tabelle erstellt wird durch das MS SQL Management Studio. Die einzelnen Schritte für den Import werden in dem Tutorial beschrieben. Für den Import wird das MS SQL Management Studio und die Zugangsdaten zur Datenbank (Host, Port, Datenbankname und Passwort) benötigt.
CSV Datei in MS SQL Server importieren

- Mit dem MS SQL Managementstudio kann man leicht CSV Datei in MS SQL Server importieren.
Über einen Rechtsklick auf einer Datenbank kann man ein Menü öffnen, in welchem sich der Menüpunkt “Task” befindet. Unter dem Menüpunkt “Daten importieren” öffnet sich ein neues Fenster in welchem man verschiedene Datenquellen auswählen kann.

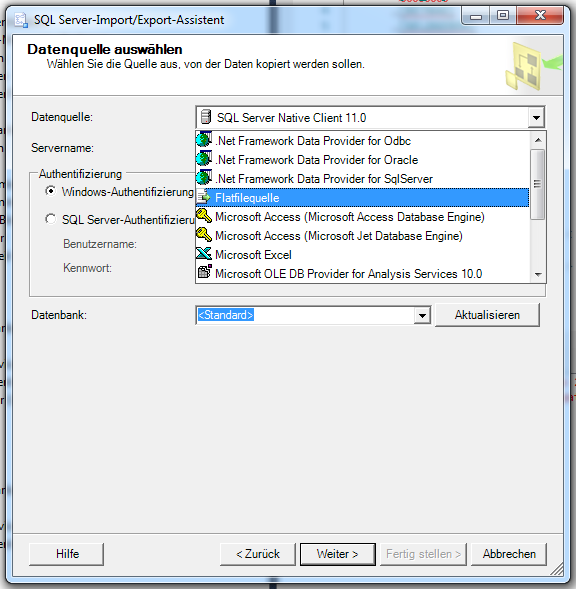
- CVS Dateien sind Flatfiles
Es öffnen sich beim Wählen des Menüpunktes, ein Assistenten in welchem man “Weiter” klickt und zur nächsten Ansicht gelangt. Wir haben nun die Möglichkeit verschiedene Datenquellen auszuwählen, für CVS benötigten wir Flatfileformat und kontrollieren ob die richtige Datenbank gewählt wurde. Je nach Selektierung der Datenquelle ändert sich das Programmfenster und weitere Angaben müssen vorgenommen werden.
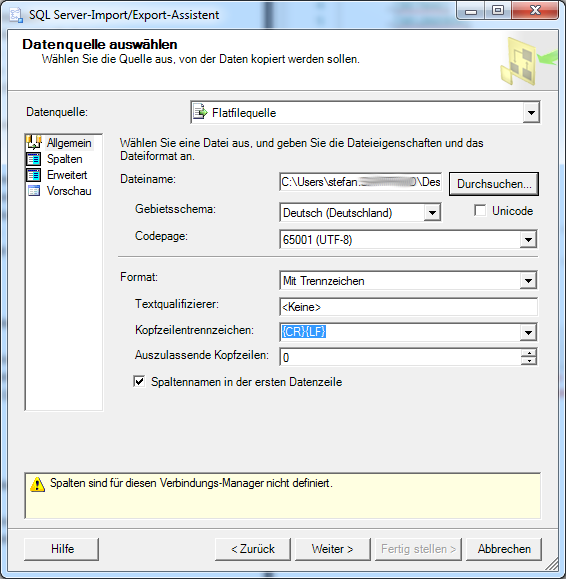
- Bei der Datenquelle muss MS SQL ausgewählt sein.
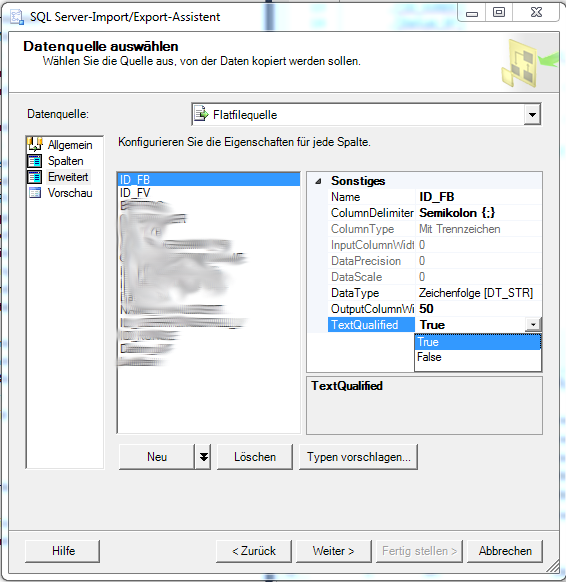
- Nach dem das Flatfileformat ausgewählt worden ist, werden die Felder in der CVS Datei angezeigt.
Im folgenden Dialogfenster wählen Wir die CVS Datei aus und navigieren anschließend zum Untermenü erweitert. Hier müssen wir für jedes Feld der CVS Datei den richtigen Datentypen auswählen, später würden die Daten falsch importiert werden.
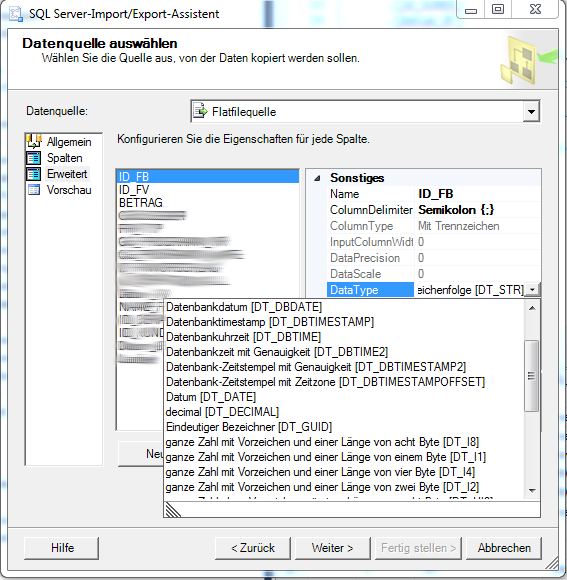
- Für jedes Datenfeld, muss der passende Datentyp gewählt werden.
Auf dem oberen Bilder kann man die Auswahlmöglichkeiten für die einzelnen Felder sehen. Der DataType beschreibt das Feld in der Datenbanksprache, wie es intern gespeichert wird.
|
Datentyp |
Beschreibung |
|
DT_BOOL |
Ein boolescher Wert. |
|
DT_BYTES |
Ein binärer Datenwert. Die Länge ist variabel, und die maximale Länge beträgt 8000 Bytes. |
|
DT_CY |
Ein Währungswert. Dieser Datentyp ist eine 8-Bit-Ganzzahl mit Vorzeichen mit 4 Dezimalstellen und einer maximalen Genauigkeit von 19 Stellen. |
|
DT_DATE |
Eine Datumsstruktur bestehend aus dem Jahr, dem Monat, dem Tag, der Stunde, der Minute, der Sekunde und Sekundenbruchteilen. Die Sekundenbruchteile besitzen einen festen Bereich von 7 Dezimalstellen. Der DT_DATE-Datentyp wird mithilfe einer 8-Byte-Gleitkommazahl implementiert. Tage werden durch ganze Zahlen dargestellt, die jeweils auf die nächsthöhere Zahl erhöht werden, beginnend am 30. Dezember 1899 um 0 Uhr Mitternacht. Stundenwerte werden als absolute Werte der Stellen hinter dem Dezimalpunkt dargestellt. Ein Gleitkommawert kann jedoch nicht alle reellen Werte darstellen. Daher ist der im DT_DATE-Datentyp darstellbare Datumsbereich begrenzt. Im Vergleich dazu enthält der DT_DBTIMESTAMP-Datentyp intern eine Struktur mit einzelnen Feldern zur Darstellung von Jahren, Monaten, Tagen, Stunden, Minuten, Sekunden und Millisekunden. Dieser Datentyp kann größere Datumsbereiche darstellen. |
|
DT_DBDATE |
Eine Datumsstruktur bestehend aus dem Jahr, dem Monat und dem Tag. |
|
DT_DBTIME |
Eine Zeitstruktur bestehend aus der Stunde, der Minute und der Sekunde. |
|
DT_DBTIME2 |
Eine Zeitstruktur bestehend aus der Stunde, der Minute, der Sekunde und Sekundenbruchteilen. Die Sekundenbruchteile besitzen maximal 7 Dezimalstellen. |
|
DT_DBTIMESTAMP |
Eine Timestampstruktur bestehend aus dem Jahr, dem Monat, dem Tag, der Stunde, der Minute, der Sekunde und Sekundenbruchteilen. Die Sekundenbruchteile besitzen maximal 3 Dezimalstellen. |
|
DT_DBTIMESTAMP2 |
Eine Timestampstruktur bestehend aus dem Jahr, dem Monat, dem Tag, der Stunde, der Minute, der Sekunde und Sekundenbruchteilen. Die Sekundenbruchteile besitzen maximal 7 Dezimalstellen. |
|
DT_DBTIMESTAMPOFFSET |
Eine Timestampstruktur bestehend aus dem Jahr, dem Monat, dem Tag, der Stunde, der Minute, der Sekunde und Sekundenbruchteilen. Die Sekundenbruchteile besitzen maximal 7 Dezimalstellen. Im Gegensatz zu den Datentypen DT_DBTIMESTAMP und DT_DBTIMESTAMP2 verfügt der DT_DBTIMESTAMPOFFSET-Datentyp über einen Zeitzonenoffset. Dieser Offset gibt die Zahl der Stunden und Minuten an, um die die Zeit gegenüber der koordinierten Weltzeit (UTC) versetzt ist. Der Zeitzonenoffset wird vom System verwendet, um die Ortszeit zu bestimmen. Der Zeitzonenoffset muss ein Vorzeichen (plus oder minus) enthalten, das angibt, ob der Offset zur UTC addiert oder von dieser subtrahiert wird. Die gültige Anzahl der Stunden im Offsetwert liegt zwischen -14 und +14. Das Vorzeichen für den Minutenoffset hängt von dem Vorzeichen für den Stundenoffset ab:
|
|
DT_DECIMAL |
Ein genauer numerischer Wert mit einer festen Genauigkeit und festen Dezimalstellen. Dieser Datentyp ist eine ganze Zahl ohne Vorzeichen und einer Länge von 12 Bytes, mit 0 bis 28 Dezimalstellen und einer maximalen Genauigkeit von 29. |
|
DT_FILETIME |
Ein 64-Bit-Wert, der die Anzahl von 100-Nanosekunden-Intervallen seit dem 1. Januar 1601 darstellt. Die Sekundenbruchteile besitzen maximal 3 Dezimalstellen. |
|
DT_GUID |
Ein global eindeutiger Bezeichner (GUID, Globally Unique Identifier). |
|
DT_I1 |
Eine ganze Zahl mit Vorzeichen und einer Länge von 1 Byte. |
|
DT_I2 |
Eine ganze Zahl mit Vorzeichen und einer Länge von 2 Bytes. |
|
DT_I4 |
Eine ganze Zahl mit Vorzeichen und einer Länge von 4 Bytes. |
|
DT_I8 |
Eine ganze Zahl mit Vorzeichen und einer Länge von 8 Bytes. |
|
DT_NUMERIC |
Ein genauer numerischer Wert mit einer festen Genauigkeit und festen Dezimalstellen. Dieser Datentyp ist eine ganze Zahl ohne Vorzeichen und einer Länge von 16 Bytes, mit 0 bis 38 Dezimalstellen und einer maximalen Genauigkeit von 38. |
|
DT_R4 |
Ein Gleitkommawert mit einfacher Genauigkeit |
|
DT_R8 |
Ein Gleitkommawert mit doppelter Genauigkeit |
|
DT_STR |
Eine NULL-terminierte ANSI/MBCS-Zeichenfolge mit einer maximalen Länge von 8000 Zeichen. (Wenn ein Spaltenwert zusätzliche Nullabschlusszeichen enthält, wird die Zeichenfolge bei der ersten Null abgeschnitten.) |
|
DT_UI1 |
Eine ganze Zahl ohne Vorzeichen und einer Länge von 1 Byte. |
|
DT_UI2 |
Eine ganze Zahl ohne Vorzeichen und einer Länge von 2 Bytes. |
|
DT_UI4 |
Eine ganze Zahl ohne Vorzeichen und einer Länge von 4 Bytes. |
|
DT_UI8 |
Eine ganze Zahl ohne Vorzeichen und einer Länge von 8 Bytes. |
|
DT_WSTR |
Eine NULL-terminierte Unicode-Zeichenfolge mit einer maximalen Länge von 4000 Zeichen. (Wenn ein Spaltenwert zusätzliche Nullabschlusszeichen enthält, wird die Zeichenfolge bei der ersten Null abgeschnitten.) |
|
DT_IMAGE |
Ein Binärwert mit einer maximalen Länge von 231-1 (2.147.483.647) Bytes. |
|
DT_NTEXT |
Eine Unicode-Zeichenfolge mit einer maximalen Länge von 230 – 1 (1.073.741.823) Zeichen. |
|
DT_TEXT |
Eine ANSI/MBCS-Zeichenfolge mit einer maximalen Länge von 231 -1 (2.147.483.647) Zeichen. |
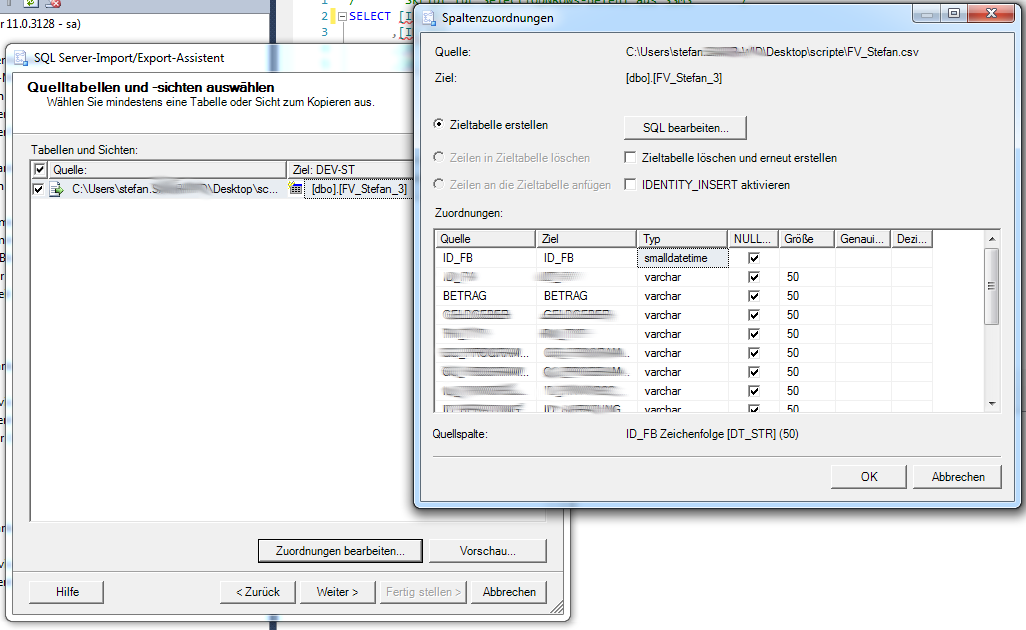
Im nächsten Schritt erstellen wir die neue Tabelle in der Datenbank. Es kann auch eine bestehende Tabelle verwendet werden. Das Ziel im hinteren Fenster (siehe Abbildung oben) kann einfach bearbeitet werden und die Tabelle anders benannt werden. Über den Button “Zuordnungen bearbeiten” öffnet sich ein weiteres Fenster (siehe Bild oben, vorderes Fenster) in welchem wir das Quellfeld (“Quelle”) und den neuen Typ für die Datenbank haben (“Typ”). Leider wird der vorher eingestellte Quelledatentyp nicht angezeigt, daher sollte man mit Bedacht die neuen Werte für das Feld – Typ auswählen.
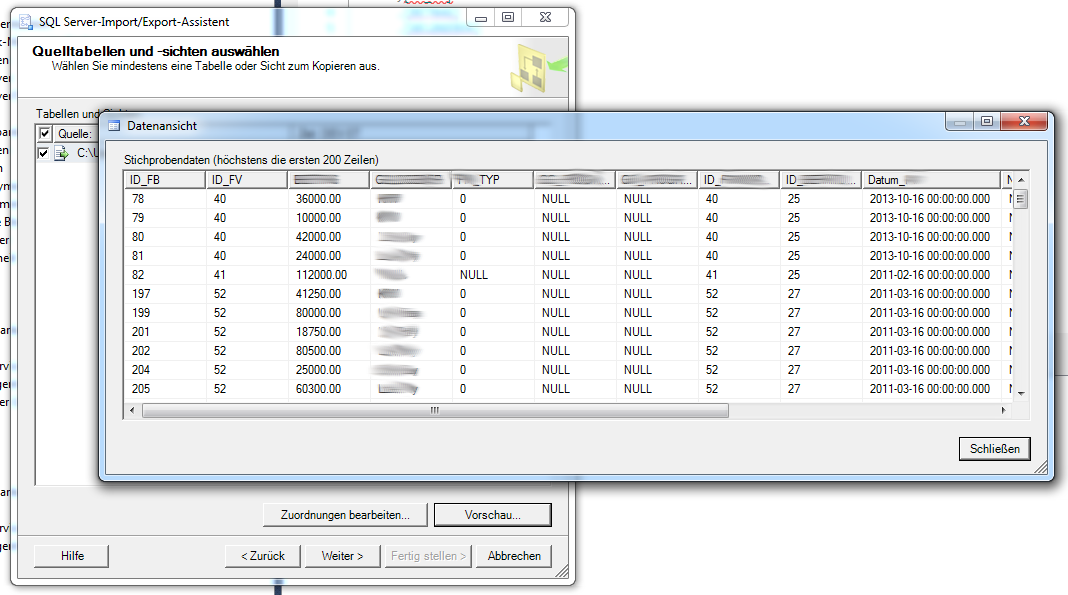
Über den Button “Vorschau” können wir prüfen, ob die Daten in die Datenbanktabelle ordnungsgemäß importiert werden.
Mit dem nächsten Klick auf den Button “Weiter >” gelangen wir zum letzten Fenster, in welchem eine Fehlermeldung oder die Felder direkt importiert werden können.
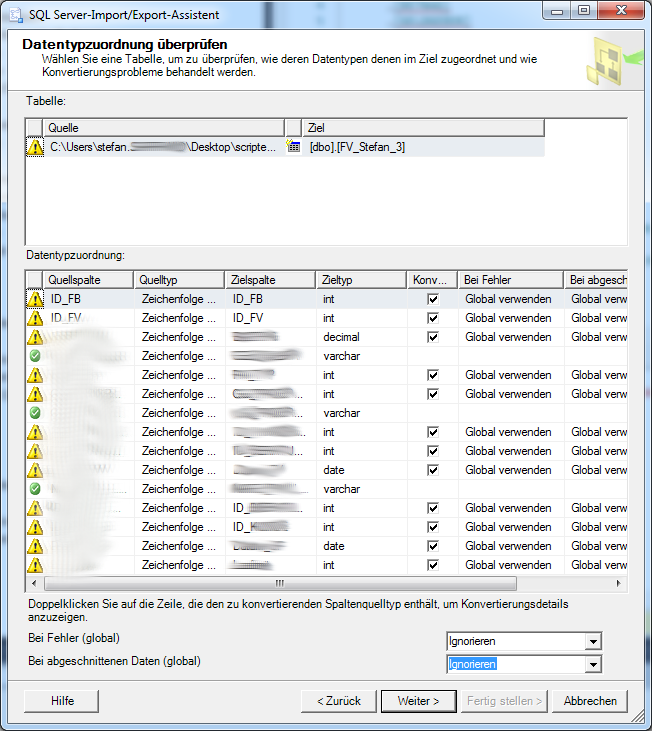
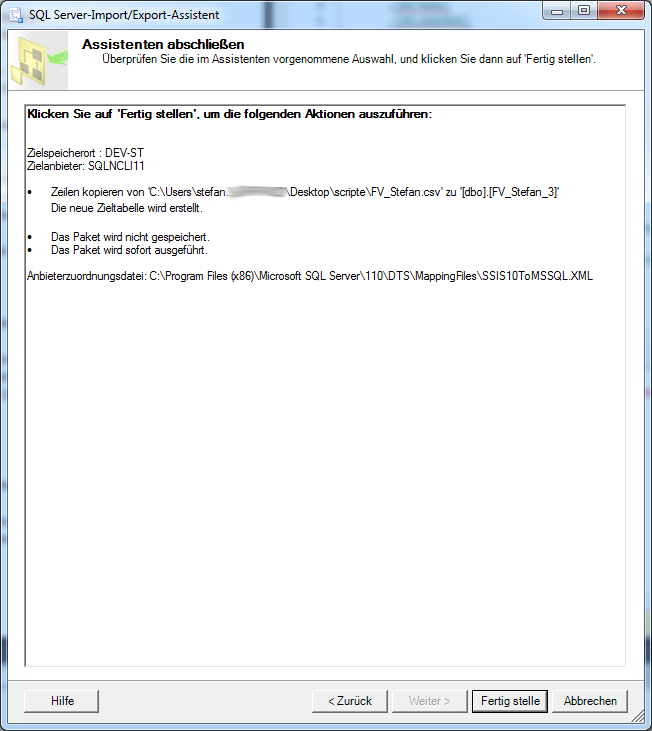
Wenn der Asistent ein Fehler findet, kann man diesen ignorieren oder versuchen diesen zu beheben (“empfohlen”). Im anderen Fall (alles richtig) werden keine Warndreiecke angezeigt.
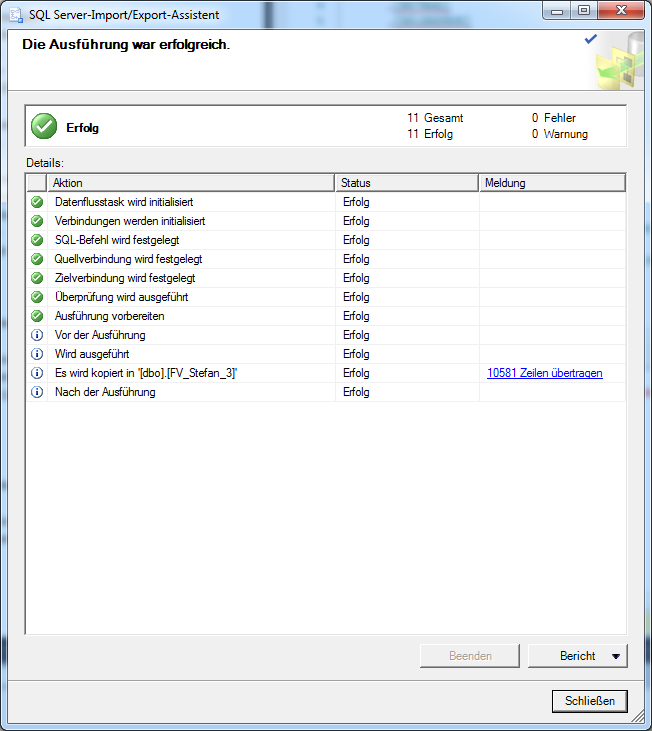
So bald die der Asistent mit dem Import fertig ist, sollte das aktuelle Fenster so aussehen und der Status immer Erfolg anzeigen. In anderen Fällen kann es passieren, das eine Datenbank angelegt wurde aber keine Daten importiert wurde. In diesem Fall empfehle ich die Datenbanktabelle wieder zu löschen und den Import der Daten von Anfang an zu wiederholen.
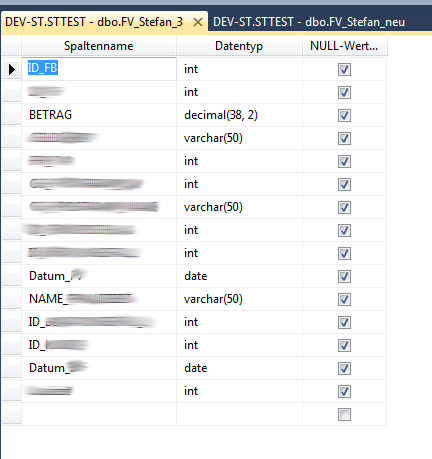
Über ein Rechtsklick auf einer Tabelle unserer Datenbank können wir ein Submenü öffnen. Hier wählen wir den Menüpunkt “Entwerfen” aus. Es öffnet sich in der Haupansicht des MS SQL Server Management Studio ein Ansicht von dem Aufbau der Tabelle, welche wir gerade erstellt haben oder einsehen wollen.

Gerade nach einem Import sollte man die Richtigkeit der importierten Daten kontrollieren. Im Bild unten können wir erkennen das die Spalten verschiedene Datentyp aufweisen. Die Datentypen können hier zur Not geändert werden, jedoch ist dies nicht zu empfehlen, da Datenverluste auftreten können.
Bulkinsert
In eine bestehende Tabelle kann ein Import von einer CVS auch mit einem Bulk-Insert vollzogen werden. Das SQL Statement könnt in etwa so aussehen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
/** Zum Ausführen dieses SQL Statements habe ich die Adminrechte verwendet. Der Nutzer muss zum Ausführen in der Rolle Bulkadmin eingetragen sein. Es wird als Pfad ein UNC Name verwendet, weil der Server die Datei sonst nicht findet. **/ BULK INSERT [II_STAT].[dbo].[neueTabelle] FROM '\\DEV-ST\temp\Zugriffe.csv' WITH ( -- Gibt die Startzeile an. FIRSTROW = 2, FIELDTERMINATOR = ',', ROWTERMINATOR = '\n' ); GO |
Quellen
http://technet.microsoft.com/de-de/library/ms141036.aspx vom 26.02.2014